A*
在求最短路的过程中,可以使用 bfs 等算法。
但是有时现在的代价已经不可能会是最优解了,或者是难以找到最优解了,但是我们还在继续搜索,这样就必然会造成资源的浪费。
怎么办呢?我们可以引入一种算法 「A*」,启发式搜索。
A* 与 bfs 基本一致,但是加入了一些很神奇的优化(这里不放代码了,直接看 bfs 的代码理解一下就行了)。
在 A* 中,我们定义估价函数
表示从起点 ,经过点 ,到达终点 的估计代价。
表示从起点 到点 的实际代价。
表示从点 到终点 的估计代价。
求出了 ,我们便可以按照 ,从小到大有顺序地搜索了。
看下图:
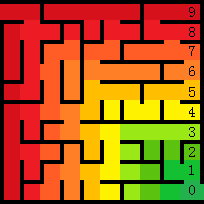
左上角为迷宫的入口,右下角为出口
而右边的数字是每种颜色所代表的 。
这时可能就有人要问了:你这估的价怎么能穿墙啊(形象理解一下这句话,实在找不到更好的措辞了)
因为我没有时间提前跑一遍迷宫来使得
所以我们可以这样简单地预处理一遍 来获得一定程度上的优化。
但是且慢
用哪种方法求都行吗?(rand)
...差不多吧,但是要满足
这里的 是指从 到终点 的实际代价
越接近 ,程序的效率就越高,走的弯路就越少。
现在想象一道题目,要求最短路。
我们先从终点开始跑一遍 Dijkstra,求出每个点到终点 的距离,作为 (即 )
然后我们再跑一遍 A* ,就可以沿着上次找到的最短路直接找到终点 了
是不是一种特别有意义的算法
显然上面这东西确实没啥意义(因为我们第一次跑 Dijkstra 就已经把最短路求出来了)
但是请记住它。
IDA*
A* 是针对 bfs 的优化,那既然是搜索,怎能缺了我们的 dfs 呢?
如果 dfs 不好优化,那我们为什么不把它改造成 bfs 呢?
于是 「 IDA*」,迭代加深+启发式搜索就出现了。
考虑一道题目必须使用 dfs,且此题需要求最小的可以解决问题的迭代深度。
显然此题我们可以直接移动格子...
考虑爆搜并统计答案,显然会炸,因为我们可能会在一条不会出现答案/深度不是最优的方案上徘徊许久,造成
现在我们可以考虑定义 为最大的迭代深度,如果当前的迭代代价 ,那么就直接结束。(现在是不是已经有 bfs 的感觉了?)
于是我们现在可以枚举 ,依次都执行一遍 dfs,这就是迭代加深,也就是 IDA* 中的 ID。
所以 ID 写完了,A* 也就是普通的启发式搜索了。由于我们的没必要使得严格使得估价函数 (毕竟是估价嘛)
所以本题的估价函数可以直接统计当前状态与期望的地图中不同的格子。
对于一个状态,我们可以当 时直接回溯,避免了运算资源的投入。
仔细观察题目,可以发现最大迭代深度是具有单调性的,如果最大迭代深度为 可以解决问题,那么最大迭代深度为 也一定可以解决问题。
那么我们就可以给 dfs 再套上一层二分了
k短路
在一些题目中,我们可能需要求的不是最短路,而是第 短的路
还是简单好吧,我直接 bfs 记录第 个到终点的不就行了
是的,确实行了,但是你可曾想过被卡掉的风险?
于是 A* 闪亮登场。
还记得 A* 一节的末尾我讲到的那种没意义的方法吗,
是的,它回来了,还带给了我们些许启发(不愧是启发式搜索)!
题意就是求一个有向图上的,从点 到点 的前 短路。
结合那个没啥意义的算法,你应该知道怎么求了吧
先建一张反向的图,然后随便跑个最短路求出
然后跑一遍 A*,每当出队的是 (终点)就输出距离,然后就没有然后了。
由于刚才我们求 跑的是最短路而不是rand,,所以 A* 的效率会奇快,然后就直接把这题切掉了。
